- Как выявить дубли страниц?
- Почему возникают дублированные страницы
- Чем опасны дубли страниц?
- Виды дубликатов
- Как избавиться от дубликатов?
- Вывод
Сейчас все хотят привлечь клиентов в интернете. Делают оптимизацию, мучаются с ней. После этого хочется выдохнуть и забыть об отладке. К сожалению, так не работает.
Каждый сайт нуждается в постоянных проверках. Посетители приходят — вот информация о трафике. Тематические ресурсы оставляют ссылки на вас — появляются контакты с внешним миром. Нужно проверять, что оптимизация работает корректно.
Добавление новой информации, актуализация старых статей повышает авторитет вашего ресурса. Однако, при перестройках структура сайта усложняется. Возникают дубли.
Допустим, была статья по теме. После обновления она стала доступна по двум разным URL. Это дубль. Поисковая система считает страницы разными из-за неодинаковых адресов.
Она недоумевает, потому что видит две страницы со схожим содержимым. Требования к уникальности у поисковиков высокие. В результате оцениваются дубли неадекватно и не могут пробиться в топ.
Здесь мы расскажем о том, как справиться с лишними зеркалами и предотвратить их появление.
Как выявить дубли страниц?

Чтобы определить, что перед вами дубль, достаточно просто взглянуть на адрес. У зеркал URL выглядит по-разному. А страничка открывается одна и та же.
Для улучшения работы сайта таких знаний недостаточно. Придётся выяснять откуда дубли взялись, как устранить уже существующие и не наплодить новых.
Найти дубли помогут поисковые системы. При сканировании роботом доступных страниц сайта, помечаются одинаковые.
Если индексация еще не произошла, то прибегать следует к помощи других инструментов. Как поступать в этом случае мы также разберем.
Ручной способ
Самый простой и интуитивно понятный путь — это ручной. Если поисковая система индексирует похожие страницы и это создает проблемы, то логичнее всего искать их с её помощью.
Делается это следующим образом:
site: your-adress.com/catalog — выдает перечень всех страниц.
Для проверки каждой группы дублей можно использовать:
site: your-adress.com inurl: target-page-pattern — это позволяет искать по схожим элементам адреса.
Надо помнить, что поиск в системах Яндекс и Google дает неодинаковые результаты. Это происходит из-за разных алгоритмов ранжирования. Лучше проверять в обеих системах.
Преимущества метода — это прямой способ проверки. Удобен, когда нужно посмотреть конкретную группу дубликатов. Для тотальной проверки ручной метод не подходит. Невозможно получить статистику по всему сайту.
Применение Яндекс.Вебмастер
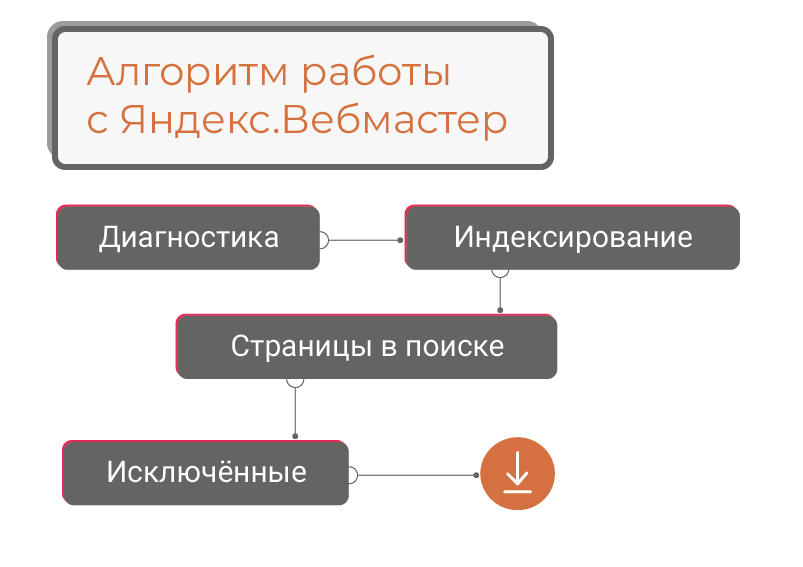
Если проверить нужно весь сайт и времени на делать это вручную нет, сильно упрощает задачу использование вебмастера. Алгоритм для Яндекса представлен ниже:
- Предупреждение в разделе “Диагностика” говорит о переизбытке дублей. Обновляются данные не сразу. Нужно подождать 2-3 дня, а потом уже проверять.
- Дальше нужно перейти в раздел “Индексирование”, и кликнуть на “Страницы в поиске”. Это откроет доступ к списку проиндексированных страниц.
- После этого перейти в “Исключённые”
- Теперь можно скачать данные в виде таблицы
- В отчете нас интересует графа статус со значением “DUPLICATE”
Информация, предоставленная вебмастером, может быть неполной. Часть одинаковых страниц не получит пометку “DUPLICATE”. К этому могут привести случайные изменения в тексте. Но убирать такие страницы тоже нужно. Тут поможет ручная проверка.
Довольно редко происходит обратная ситуация. Непохожие страницы помечаются “DUPLICATE”. Таких надо отслеживать. Обычно это явление временное и пропадает через некоторое время.
Аналогами проверки через вебмастер можно считать использование краулеров, таких как Xenu. Они подойдут, если с обновления прошло мало времени и информация об индексировании не успела обновиться.
Почему возникают дублированные страницы
Чтобы убрать ошибку — надо знать, где она произошла. Чтобы узнать — нужен примерный план проверки. Ниже обсудим основные места возникновения ошибок, приводящих к дупликации.
Применение CMS
CMS сильно упрощает жизнь создателю сайта. Однако, для корректной работы сайта движок должен быть правильно настроен. Иначе он будет источником проблем.
Движок создаёт ссылки и работает в том числе на поддержание внутренней иерархии. Системы очень разные, у каждой свои особенности работы. При изменении правил создания URL могут возникать дубли. Пример: если при переходе на ЧПУ не убрать старый вариант, то появятся зеркала.
Полезную информацию о системах управления содержимым и создании сайта с нуля можно найти в нашей статье.
Технические ошибки
Проблемы могут возникать из-за неправильных настроек сайта. Самые банальные — ненастроенные редиректы и канонические страницы.
Часто встречается индексация служебных выражений в составе адреса вроде UTM-меток. В норме, какая метка выводится в URL не важно. Индексируется одна страница. При неправильной настройке возникает огромное количество зеркал.
Другой пример — это признание дублями страниц, не имеющих общего содержимого. Мы уже упоминали выше, что такое возможно. Причина — сбой кода ошибки. Из-за него временно недоступные страницы индексируются как идентичные. Тут необходимо совпадение времени проверки сайта и появления ошибки.
Человеческий фактор
При добавлении новых страниц, организации внутренних ссылок может происходить дублирование статей. Ошибка в этом случае допущена человеком. Проверять надо не только за CMS и настройками сайта.
Пример — это некорректное указание ссылки. Достаточно упомянуть при организации внутренней перелинковки не основной домен, а с добавлением www.
При структурных перестройках обычно остаются старые страницы. Место в иерархии они будет занимать другое, но из-за человеческой ошибки могут вызываться и по старому адресу.
Чем опасны дубли страниц?

Теперь стоит поговорить, к чему приводит большое количество зеркал. Основной повод для беспокойства — неправильная индексация. Вместо одной страницы появляется несколько очень похожих. В результате поисковик снижает общие оценки сайта.
Что именно не нравится поисковой системе:
- Наполнение больше не уникально
- Падает значимость источника
- Похоже на спам — так как появляется переизбыток ключевых слов определённой группы.
О важности уникальности контента можно узнать в нашей статье.
Очень большое количество дублей приводит к бану от поисковой системы. Она считает такое попыткой оккупировать несколько мест в выдаче. Поэтому нельзя запускать проблему с дублями. Но надо отметить, что санкции — штука редкая, поисковые системы не бьют тревогу сразу.
Как поисковик обходится с дублями: он чистит выдачу от зеркал — то есть не дает одновременно в поиске выпадать одинаковым станицам. Однако, может меняется выпадающая в выдаче станица — вчера было одно зеркало, сегодня другое. Такие флуктуации приводят к размазываю трафика между зеркалами.
Как это работает. У нас есть две или больше страницы с идентичным содержимым. Для посетителя сайта текст URL значит мало, так что он не заметит разницы. Заходит он на ту, что раньше появляется в выдаче. Если бы станица была одна, то весь этот трафик бы суммировался и шёл на неё. Тут же их 2 или больше — трафик на каждую сильно ниже, чем в случае отсутствия зеркал. А ранжируется каждый дубликат отдельно.
Ссылки на зеркала усугубляют ситуацию — они мешают их сокрытию и не способствуют увеличению трафика на канонической странице. Чем дольше существует дубль, тем сильнее он обрастает ссылками. И тем сложнее всё исправить и склеить зеркала.
Из-за дублей появляются лишние страницы. Таким образом растет количество работы для робота. В один заход он может проверить только определенное количество страниц. Получается, что чем больше дублей, тем дольше идет индексация.
Кроме того, хуже работает вебмастер. На него сильнее нагрузка. И невозможно пользоваться бесплатными версиями краулеров. У них есть ограничение на количество проверенных страниц.
Виды дубликатов
Оценка внешнего вида — эффективный способ подбора решения для избавления от дубля. Ниже мы рассмотрим, какие они бывают.
Полные
Так называются страницы с идентичным содержимым. Естественно, при этом у них совпадают еще и метатеги Title & Description.
Ошибки и изменения в тексте URL, возникающие при автогенерации или ошибочном ручном введении могут быть разными. Самые распространенные:
- Замена http на https
- Слеш на конце (не имеет значения, если это главная страница)
- Добавление/утрата www
Менее частые, но тоже возможные искажения — это смена регистра:
CAPS на caps
и замена дефисов на подчеркивания:
like_that на like-that.
Также могут появляться лишние символы в адресе:
www.domain.ru/target будет www.domain.ru/target3f47
или меняться уровни вложенности: теряться или меняться местами.
www.domain.ru/target/page0 будет www.domain.ru/page0/target
Отдельно упомянем динамические параметры. Они в норме индексируются единожды. При нарушениях — порождают зеркала.
Неполные
Частично дублируется содержимое. Механизмы могут быть те же, что и при полных. Доля различия тогда возникает из-за постоянно меняющихся элементов на странице. Это могут быть шторки новостей, например.
Причинами возникновения неполных копий могут быть такие удобные для пользователя функции, как:
- Поиск
- Пагинация
- Мобильная версия, смена языка или региона
- Фильтры
Все они делают в конце адреса служебные пометки. По этому свойству их легко узнать и объединить в одну группу.
Почему так важно знать, полная ли копия? Есть инструменты избавления от дублей, которые работают только на тождественные страницы и бесполезны для неполных замен.
Отдельно поговорим про карточки похожих товаров — это разные страницы, но если различие только в размере или цвете, то описания будут похожи. Из-за этого страницы будут признаны дублями.
Исправлять это с помощью методов избавления от дублей неправильно. Обычно в этих случаях реорганизовывают каталог, склеивают вместе такие товары и делают общую карточку. Другой путь — уникализировать описания на каждой странице.
Как избавиться от дубликатов?
Мы разобрали основные типы зеркал. Теперь обсудим, что с ними делать. Инструментов несколько и применять нужно наиболее подходящий.
Редирект 301
Он позволяет не убирать дубликат из индексации. На первый взгляд может показаться, что плохо — так как мы не добиваемся своей цели. Мы не уничтожаем дубль. Он остаётся, а пользователя перекидывает на основную страницу. Постепенно снижается положение зеркала в выдаче.
Это на самом деле полезное свойство, если на дублирующую страницу были ссылки в сторонних источниках. В этом случае уничтожить зеркало значит лишиться ссылки.
Редирект оформляется в теле страницы. Исключение — использование Apache. У таких сайтов есть .htaccess, в котором можно прописать указания регулярными выражениями.
Избавляясь от дублей не прибегайте к временному редиректу 302. Он, в отличие от 301, не будет вообще передавать вес ссылок и трафик на основную страницу (при 301ом передаётся часть). Также для страницы с 302м редиректом не будет снижения позиции в выдаче.
Избыток перенаправлений не улучшит положение: будет перегружен сервер. Так нельзя убрать индексируемые страницы с динамическими параметрами.
Каноническая страница
Есть способ пометить правильное зеркало, не делая редиректов. То есть посетителя не перекинет автоматически на основную страницу. Такая пометка показывает, что нужно индексировать в первую очередь и передает полный вес.
Оформляется в коде заголовка страницы следующим образом:
<link rel=»canonical» href=”https://www.domain.ru/target/”>
Ограничение этого способа: дубль с атрибутом «canonical» и каноническая страница должны быть одинаковы. Иначе команда не сработает. Такой способ стоит применять для динамических параметров.
Google нравятся редиректы и канонические страницы. Он считает их лучшими способами борьбы с дублями. Описанные ниже способы — не жалует.
Запрет индексации
Здесь поговорим о методах склеивания зеркал, рекомендуемые Яндексом. Тут принципиально другая идея. Мы не показываем, где искать основную страницу. Мы убираем из поиска лишние.
Как этого можно добиться? Проще всего — не показывать роботам дубли страниц. Это можно сделать через robots.txt. Без прохождения проверки невозможно оказаться в выдаче поисковика.
Оформляется регулярными выражениями через директиву “Disallow”.
Есть другой вариант, применяемый при работе с GET-параметрами. Это что-то среднее между атрибутом «canonical» и директивой “Disallow”: даёт ссылку на канонический вариант и при этом запрещает индексацию.
Используется другая директива всё в том же файле. Называется она “Clean-param”. Если канон не был проиндексирован, то это повысит шансы, что его проиндексируют в ближайшее время.
Третий способ — использование мета-тега “robots”. Его прописывают в заголовке страницы. В сочетании с параметром “noindex” он делает то же самое, что и “Disallow”.
Можно использовать и другой параметр. Если “noindex” закрывает двери для входа на страницу, то “nofollow” — для выхода. Робот не сканирует исходящие ссылки. То есть он не может совершить переход вглубь сайта.
Нельзя посылать роботам противоречивые команды. В приоритете у них директивы из robots.txt.
Заполнение файла с указаниями для всего сайта — дело сложное. Например, если после директивы “Disallow” и слеша не написать ничего, то робот не зайдёт никуда. Сайт будет полностью недоступен ему. Поэтому мета-теги могут быть удобнее.
Описанные в этом разделе способы не нравятся Google. Если есть внешние ссылки, то страница может выпадать в поиске. В рекомендациях по избавлению от дублей просят не убирать их из индексации, так это ограничивает возможности анализа. Скрытые страницы считаются уникальными по умолчанию. Таким образом мы вводим в заблуждение алгоритмы.
Поисковым системам нравятся разные подходы. Можно и нужно попытаться угодить всем целевым. Тогда в robots.txt придётся указывать отдельно все параметры для каждой. “По умолчанию” в этом случае будут игнорироваться.
Не следует пугаться фразы про необходимость что-то писать в коде страницы. Залезть в тело каждой не нужно. Всё, кроме robots.txt, редактируется через CMS для всего сайта.
Вывод
Дубли страниц вредны: усложняют работу сервера, ухудшают ранжирование, не дают пробиться в топ и привлечь посетителей. От зеркал необходимо избавляться. Нельзя запускать — это усугубит ситуацию.
Чеклист по тому, как это делать:
- Найдите зеркала вручную или через вебмастер
- Какие у них особенности?
- Почему они появились?
- Что можно с ними сделать?
- Какие поисковые системы устроит ваше решение?